- HOME
- 데이터공유
- 형태소사전
형태소사전
형태소사전(NIADic)이란?
기존 형태소 사전의 부족한 단어 수를 보완한 새로운 형태소 사전(NIADic) 을 개발해 제공함으로써 자체 형태소 사전 개발이 어려운 중소기업, 스타트업, 연구소, 학교에서 정확도 높은 텍스트 분석 가능
기존 형태소 사전
(37만 단어)
NIADic
(93만 단어)
시스템 사전(28만)
세종 사전(9만)
기존 형태소 사전
전문분야 단어 추가
(신조어, 법률, 의료 등)
기존 형태소 사전(SejongDic)과 NIADic의 텍스트 분석 결과 비교
| 문서 종류 | 세종Dic | NIADic |
|---|---|---|
| 이문열의 삼국지 1권 분석 (단어연관성 비교) | 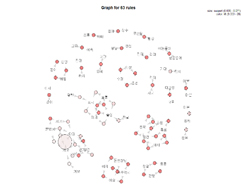
|

|
- NIADic을 사용하면 Sejong Dic 대비 적게는 2.56배~ 5.36배의 형태소가 발생하므로 더 정확한 결과 도출 가능
- 어휘의 상호연관성 정도에서는 NIADic이 Sejong Dic 대비 2.3배 ~ 5.176배 정도로 많은
어휘량 간의 연관성을 보여줌
따라서 연관성 분석을 통한 인사이트 창출 시 효과적
형태소사전(NIADic) 도입 효과
| 형태소 사전(NIADic) 도입 전 | 형태소 사전(NIADic) 도입 후 |
|---|---|
|
|